Recently, my team has been working on implementation related to identity verification (eKYC), and how to handle variant characters in names and addresses has been a hot topic. In Japanese, the same kanji can have subtly different shapes. These are called variant characters.
The 異体字検索漢字リスト published by Japan's Ministry of Health, Labour and Welfare is a useful reference (there are actually many more variants than the list covers).
It seemed difficult for a person to quickly judge whether a variant character shown on an identity document and a kanji character manually entered by a user refer to the same character, especially if they have to check sources like the PDF above every time. So I made a simple web tool for this.
You can try it at https://moji.stenyan.dev/.
What is "MJ縮退マップ検索"?
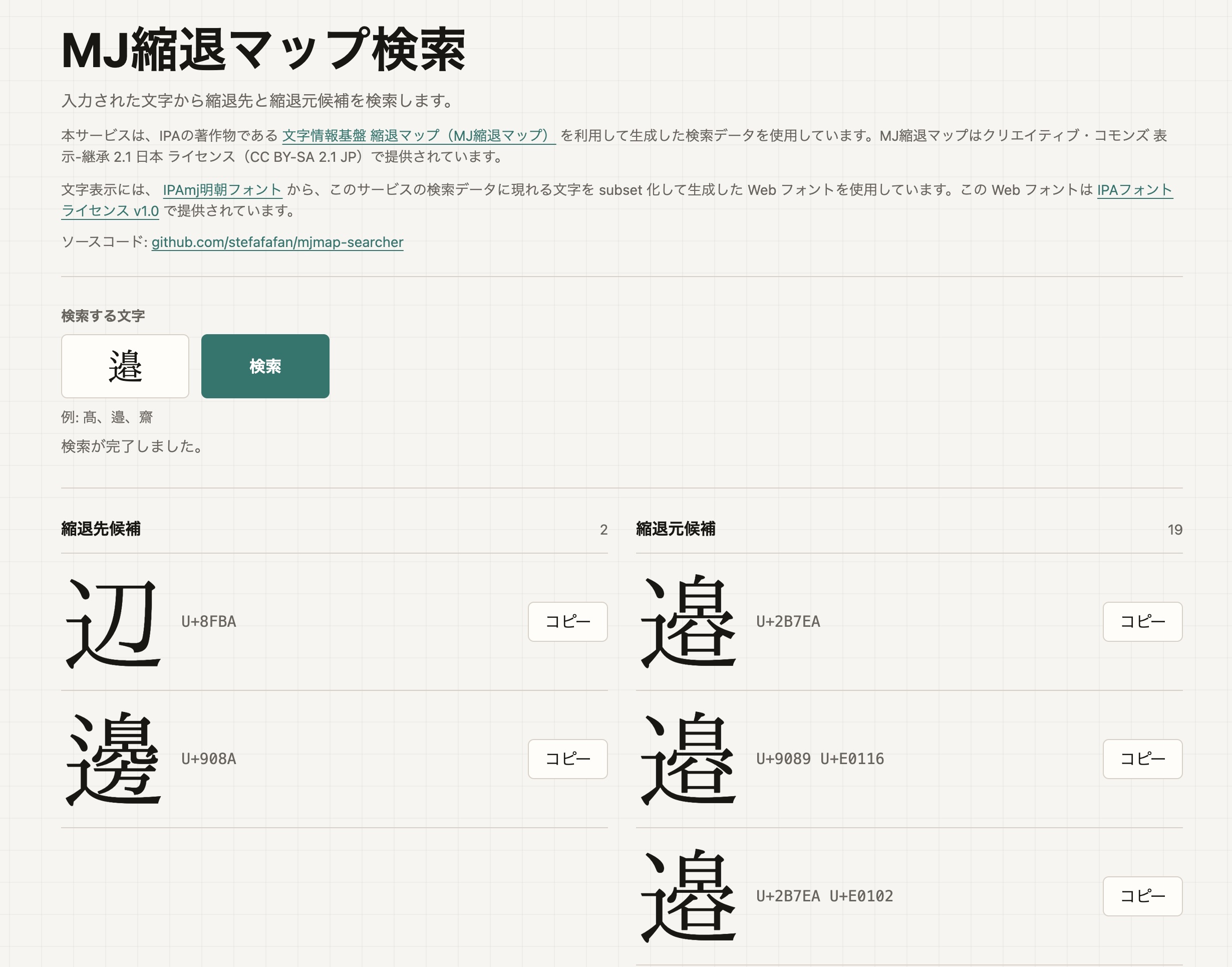
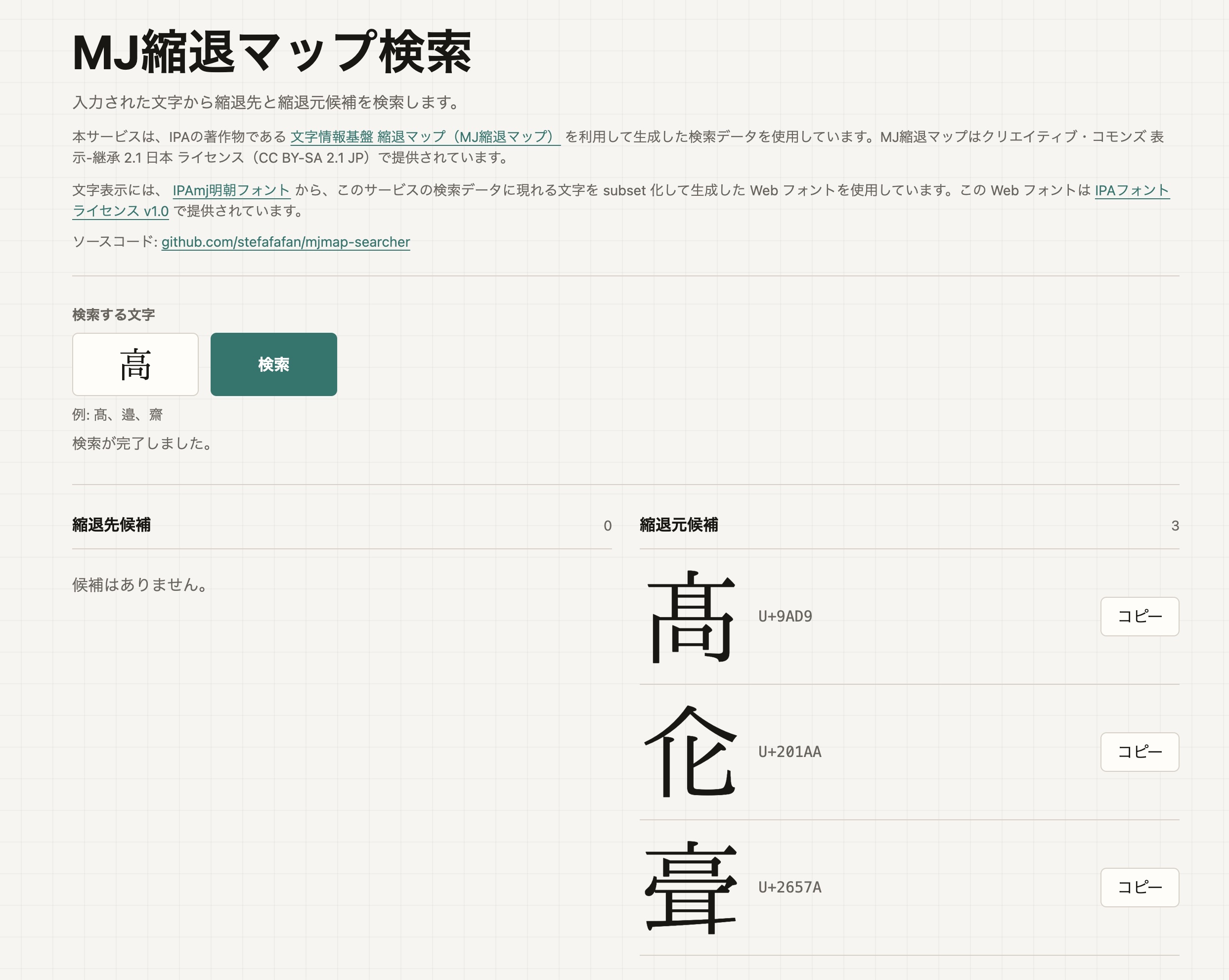
The 文字情報技術促進協議会 publishes a dataset that fits this use case well.1 For example, it can show that the corresponding character for "邉" in "渡邉" is "辺", or for "髙" is "高".
Using this dataset, I made a tool that can search both target and source candidates at once. This made it easier to look up the relationship between a specific character and its candidates.2
As a side note, depending on the font, some characters may fail to render and appear as "tofu glyphs". The 文字情報技術促進協議会 also provide a font to avoid that,3 and this tool uses it as well.
Footnotes
-
https://moji.or.jp/mojikibansearch/basic also has a search page, but it did not seem to provide a way to fetch both target and source candidate results at once, so I made a separate tool. ↩